目前,X射线的计算机断层成像(computed tomography, CT)技术依然是一种重要的医学成像手段,能够清晰的呈现病人的几何解剖结构。然而,CT图像的质量与X射线的辐射剂量有关,较高的剂量会增加病人罹患癌症等基因疾病的几率。为了降低辐射剂量,减少投影角度是一个直接有效的方法,但是这种方法在利用传统解析算法进行重建时,采样率的降低会导致重建图像中产生严重的混叠伪影,影响医生的诊断和治疗。
在已经提出的用于解决欠采样投影重建问题的重建算法中,基于字典学习的方法是一种近来提出的重建算法。该算法是将待重建的CT图像划分为大小相等并且互相重叠的小图像块,以同一个过完备字典为基底,计算这些图像块的稀疏表示,利用字典学习方法提取图像的稀疏性,求解低剂量的欠采样重建问题。然而,现有的字典学习重建算法的正则约束项是L2范数(L2范数表示向量中每个元素平方和的开方,即欧式距离)下的稀疏约束,对图像的稀疏特性提取的并不彻底,当采样率进一步降低时,会引起重建图像的低对比度细节丢失,质量明显下降。
最近,苏州医工所医学影像室郑健课题组的章程等人提出了一种基于L1范数(L1范数表示向量中每个元素绝对值的和)稀疏约束的字典学习重建算法。利用L1范数更好的稀疏特性,降低原算法中L2范数约束引起的过平滑效应,保留更多的图像细节信息。提出的算法利用加权策略转化为带权重的字典学习重建函数,利用迭代加权最小二乘法(iteratively reweighted least squares,IRLS)进行求解。
实验结果表明,与已有的基于L2范数的字典学习重建算法(ADSIR)以及其他两种典型的重建算法(GPBB,SART)相比,提出的算法得到的重建结果更精确,尤其在进一步降低采样率的条件下,得到的结果与对比算法相比有明显的提升,说明L1范数的约束对于图像稀疏特性提取的有效性。
以上研究得到国家自然科学基金(批准号:61201117,61301042)、江苏省自然科学基金(批准号:BK20151232)和苏州科技项目(批准号:ZXY2013001)的支持,相关结果发表在Biomedical Engineering Online杂志2016年度期刊。
文章链接:https://biomedical-engineering-online.biomedcentral.com/articles/10.1186/s12938-016-0193-y
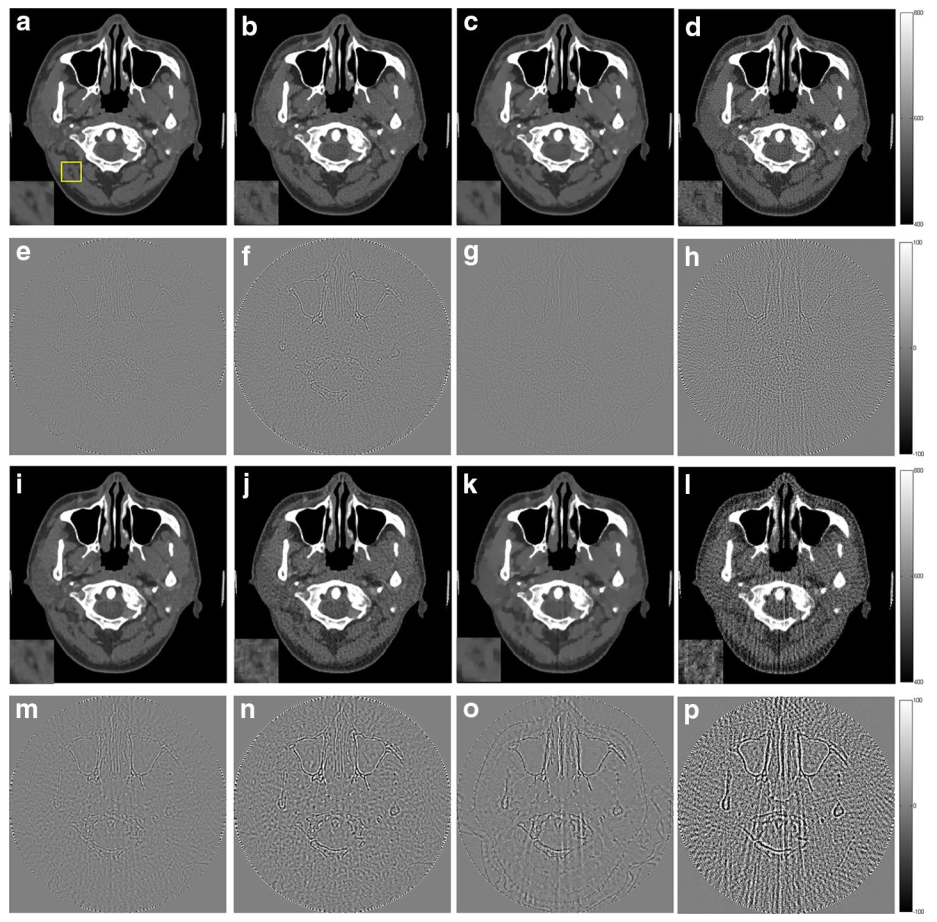
图1 人体头部切片的重建结果。a-d为180个采样角度下的重建结果,从左到右分别为本文提出的L1-DL算法,ADSIR,GPBB,SART;e-h为图像(a-d)与原始图像的差异图像;i-l为90个采样角度下的重建结果,从左到右分别为本文提出的L1-DL算法,ADSIR,GPBB,SART;m-p为图像(i-l)与原始图像的差异图像.由图可见,本文提出的算法得到的重建图像在黄色边框的放大区域,更好的保留了细节信息,同时重建图像和原始图像的差异最小,这种优势在进一步降低采样率时(90个采样角度)表现的更加明显。
 附件下载:
附件下载:
