引言:模型可解释性已成为机器学习管道的基本部分,它使得机器学习模型不再是"黑匣子"。幸运的是,近年来机器学习相关工具正在迅速发展并变得越来越流行。 Lundberg 和 Lee (2016) 的 SHAP(Shapley Additive Explanations)是一种基于游戏理论上最优的 Shapley value来解释个体预测的方法。 Shapley value是合作博弈论中一种广泛使用的方法,它具有令人满意的特性。

一、机器学习模型与其可解释性:
机器学习可解释模型可以分为事前模型和事后可解释模型两大类。
事前模型:包括可解释模型,如线性、决策树和基于规则的模型,以及同样透明的更复杂的模型。线性回归模型(如OLS、岭和LASSO)具有可解释性,因为它们可以根据它们在局部和全局上的b系数被直接解释。假设数据已经标准化并且模型不包含截距,b的大部分可以被解释为与回归任务相关的特征。值得注意的是,解释能力受到共线独立变量的影响,因为在这种情况下,与目标变量无关的特征会被赋予较大的权重。如非负性和正则化可以用来限制解集,从而可能简化模型并提高可解释性。
事后可解释模型:事后模型代表了最广泛的一类可解释性方法,广泛使用的黑盒模型可解释性方法是基于扰动的方法,如SHAP,旨在为黑盒模型建立替代模型,为它们提供可解释性。SHAP利用Shapley值的思想对模型特征影响评分,考虑实例的所有可能预测,使用所有可能的输入组合。由于这种详尽的方法,SHAP可以保证一致性和局部准确性。
二、SHAP
SHAP值基于Shapley值,Shapley值是博弈论中的一个概念。但博弈论至少需要两样东西:一个游戏和一些玩家。这如何应用于机器学习的可解释性?假设我们有一个预测模型,然后:
“游戏”是复现模型的结果
“玩家”是模型中包含的特征
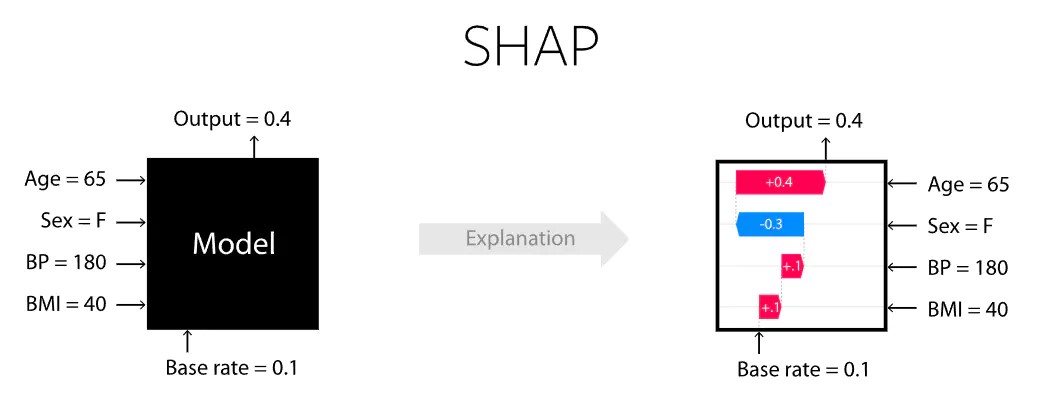
Shapley所做的是量化每个玩家对游戏的贡献。SHAP所做的是量化每个特征对模型所做预测的贡献。
需要强调的是,我们所谓的“游戏”只涉及单一的观察样本。一个游戏:一个观察样本。实际上,SHAP是关于预测模型的局部可解释性的。
三、SHAP安装与简单实现
安装方式:pip install shap
conda install -c conda-forge shap
操作流程:
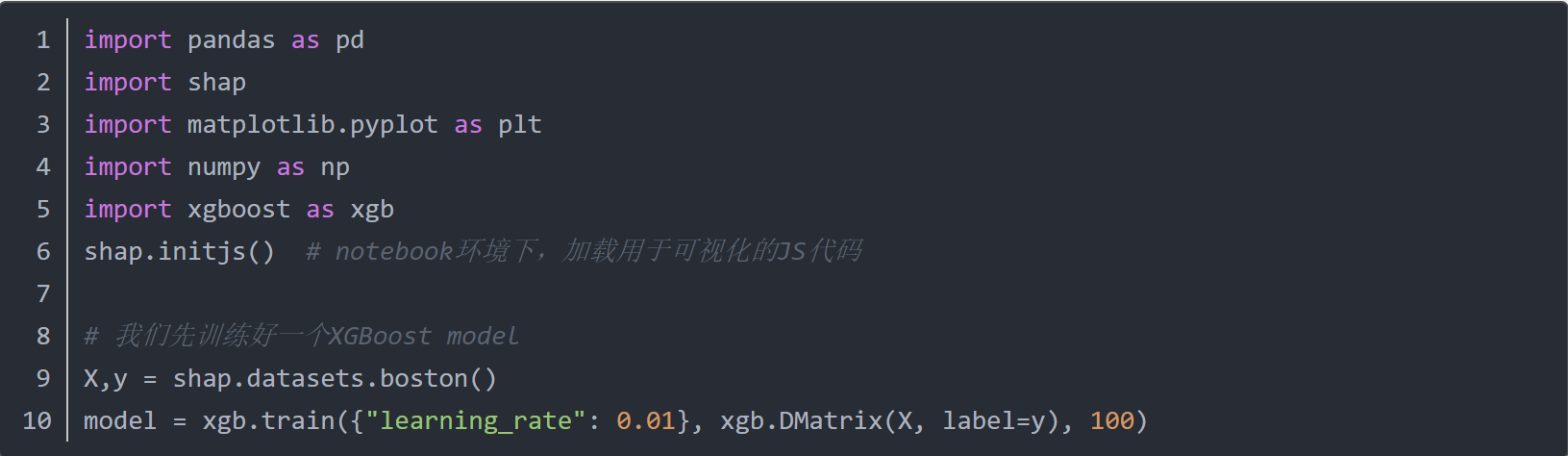
1.以Boston房价为数据集举例,导入库与数据集并训练XBGoost模型
2.创建Explainer:在SHAP中进行模型解释时,需要创建一个explainer,SHAP支持很多类型的explainer,如deep、gradient、kernel、linear、tree、sampling,其具体应用范围如下图所示。

3.以支持常用的XGB、LGB、CatBoost等树集成算法的tree为例,代码如下所示。

若使用kernel explainer,需要注意的是,该explainer虽然适用于任何模型,但是其性能不一定是最优的,计算速度会很慢,但是可以通过K-mean聚类算法对数据集进行summarizing,这样可以有效提高kenel的速度,当然,这种做法是以牺牲一定准确性为代价的。
4.单个Prediction的解释:SHAP提供极其强大的数据可视化功能,来展示模型或预测的解释结果。
![]()

上图的"Explanation"展示了每个特征的贡献程度,图上有base value 以及最终的f(x)值,红色表示为正向作用,蓝色表示为负向作用,模型将预测结果从base推动到了f(x),推高的特征用红色表示,将预测推低的特征用蓝色表示。
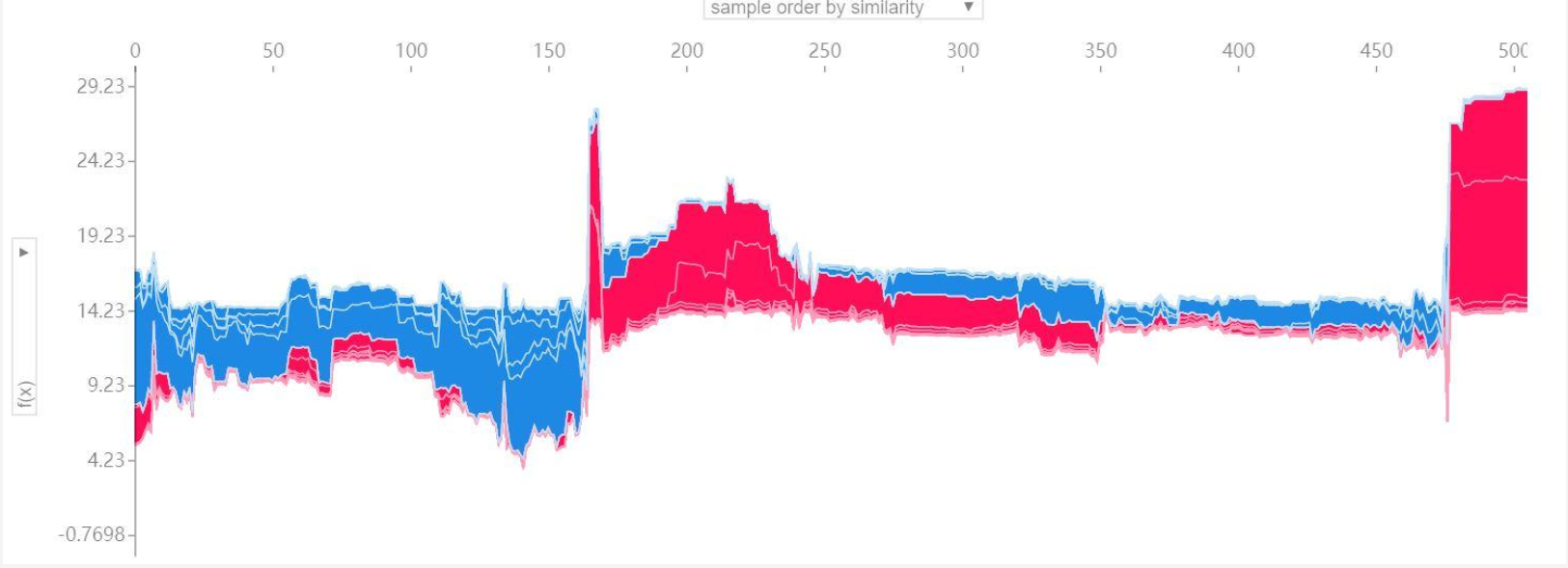
5.多个预测的解释:要对多个样本进行解释,将上述形式旋转90度后并排放置,就可以看到整个数据及的explanations:
![]()
6.特征重要性(Feature Importance)
SHAP提供了特征重要性的计算方式,取每个特征的SHAP值的绝对值的平均值作为该特征的重要性,得到一个标准的条形图(multi-class则生成堆叠的条形图)
![]()

从上图可以看出,LSTAT、RM、CRIM的特征重要性最高,必须保留,而CHAS、ZN、RAD三个特征的重要性最低,可以考虑删除。
回顾与总结
本文介绍了可解释机器学习模型的类型,SHAP的基本原理,以及常用的基本SHAP可视化机器学习模型解释性的流程,SHAP还有许多数据可视化功能值得进一步挖掘探索,如Interaction values、Dependence plot等。
参考资料:
https://www.freesion.com/article/19421441608/
https://www.jianshu.com/p/1a3fdffc63f2
 附件下载:
附件下载:
